The problem of 3D layout recovery in indoor scenes has been a core research topic for over a decade. However, there are still several major challenges that remain unsolved. Among the most relevant ones, a major part of the state-of-the-art methods make implicit or explicit assumptions on the scenes --e.g. box-shaped or Manhattan layouts. Also, current methods are computationally expensive and not suitable for real-time applications like robot navigation and AR/VR.
In this work we present CFL (Corners for Layout), the first end-to-end model for 3D layout recovery on 360º images. Our experimental results show that we outperform the state of the art relaxing assumptions about the scene and at a lower cost. We also show that our model generalizes better to camera position variations than conventional approaches by using EquiConvs, a novel type of convolution applied directly on the sphere projection and hence invariant to the equirectangular distortions.
In this work we use ∼500 panoramas from the SUN360 dataset that were labeled by
Zhang et al.. Since all panoramas were labeled as box-type rooms, we hand-label and substitute some of them representing more faithfully the actual shapes of the rooms. We do line thickening and Gaussian blur for easier convergence during training since it makes the loss progression continuous instead of binary. In the figure below we show an example.
We have released the TensorFlow based implementation on our github page. Try our code and learn everything about
EquiConvs, a novel implementation of the convolution for 360º images that adapts the shape of the kernel accordingly to the equirectangular projection distortions.
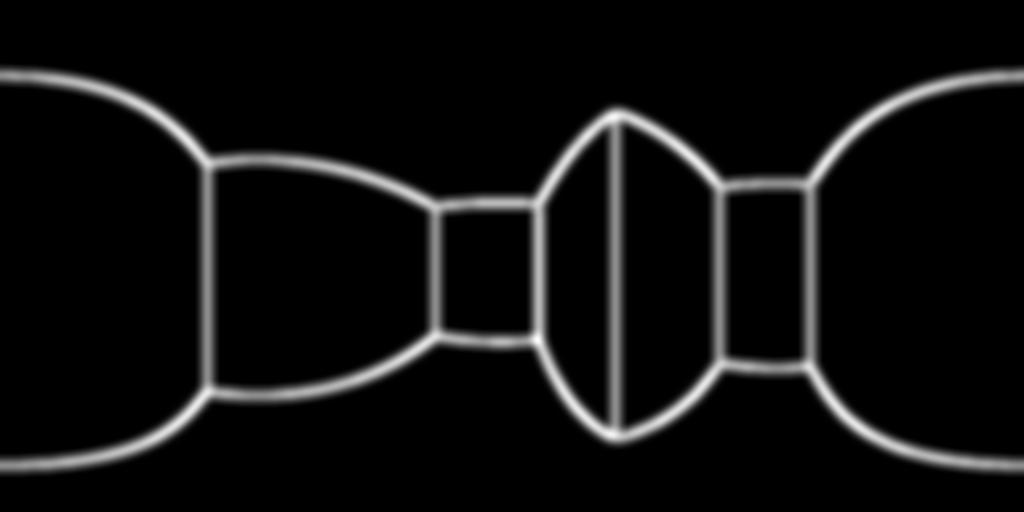
Padding effect using StdConvs and EquiConvs
|
|
The aim of this video is to show, for each tested panorama, the predictions obtained through our two CFL models, StdConvs and EquiConvs, when each panorama is rotated from 0°to 360°.
With EquiConvs, we do not use padding when the kernel reaches the border of the image since offsets take the points to their correct position on the other side of the 360 image. This allows the model to understand the continuity of the scene producing much more consistent predictions along all the performed rotations.
StdConvs, instead, by using zero-padding, lose this consistency. As a consequence, in most cases when corners approach the borders, StdConvs predict these corners twice, i.e. at both ends.